



By Ammar Khan
Deep Learning is one of the most resource hungry gorillas today in terms of compute, memory, and dataset size required to build models. If you are curious enough to automate your platform in terms of labeling data that is coming and leaving on-the-fly, Deep Learning is the modern-day magic to make it happen. But you might not have the suitable amount of data to train these models and maybe not enough compute and memory resources to make it happen.
Deep Learning models are roughly based on the human mind. Over the centuries, people do not need to reinvent the wheel each time from the start. We read history to learn about the solutions that helped solve the problems in the past. We write history for future generations too. Human genes do that part as well. It encapsulates the requirements of today and adjustments are made in the inherited gene structure. We already have protection from most of the diseases that our parents had, and our bodies restructure the inherited part for future generations as well. This is a continuous progression with minor additions into the whole genome structure that was already functional.
Deep Learning adds something like that under the umbrella of ‘Transfer Learning’. There is a whole set of complex algorithms carefully crafted for problems at hand and are trained on terabytes and petabytes of data. We can leverage this as a layer in our already trained model, and with very limited resources, we can make our personal models with a smaller data set using a previously trained, more complex model.
The Assumed Problem:
Let’s say we are running a platform where we are asked to separate dog and cat images users upload and label them on-the-fly. But we only have 100 or 200 MB of data available in our platform. This is not enough to train a Deep Learning model. But we can leverage a Transfer Learning model that has already learned enough for a much larger problem. We are going to import this as a layer and feed our data into the part of the problem we want a solution for.
Solution:
VGG16 is a Deep Convolution Neural Network was designed to solve complex image recognition problems. It was trained using IMAGENET data set which comprises of 15 million labeled high-resolution data set with 22,000 categories. The architecture for VGG16 is:
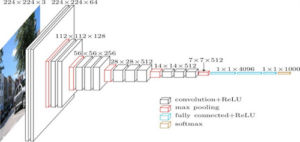
We do not have this amount data to train the algorithm, nor do we have the resources to actually train this deep neural network. What we are going to do is to import it as a layer in our already trained model and use it for our binary classification of cats and dogs. We prepare our dataset of 2000 training images and 1000 test and validation images of cats and dogs. Importing the VGG16 as the top layer in our model and using a dense layer and an output layer to filter large network in our problem. This is what the network looks like:
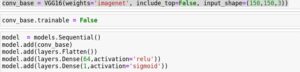
As you can see, we have frozen the VGG16 part from the training, as we do not wish to train this giant network. It will already have pre-learned weights from IMAGENET. The only trainable layers are the Dense and the output layer. Let’s train the model using the following parameters:
![]()
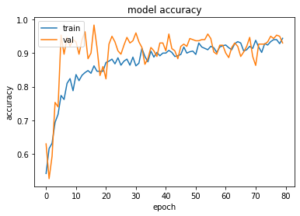
In about half an hour of training on a 4 core / 16 gig i5 machine, the model yielded the following training and validation graph.
Let’s check the accuracy of the model on our test set:
![]()
The model yielded an accuracy of 89.4% on the test set and 94.4% accuracy on the training and validation set. This is quite amazing. Let’s check this in terms of the actual score of predictions on the test data set of 1000 images of cats and dogs. We are going to use confusion matrix for that:
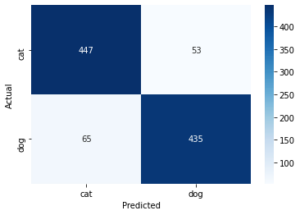
As you can see the two dark blue shades showing correctly identified cat and dog images. The error is quite low as the model accurately identified 882 images into two categories successfully with little effort. As you can see, these models can be added to a pipeline where incoming data can be sorted on the fly by querying the model.