


![]()
There is No denying that now the most and spoken about term in today’s technical world is data science. One “google search” and it returns millions of learning platforms, bootcamps, job post, graphs, pictures, blogs and companies offering various services on data science and what not. Here, my humble try is to cut through those mega-technical words and all the “fluff” and try to explain the terminology and “demystify” the process. My hope is this will help you to build and understanding around it and help you to make informed decision in case you are looking for a career choice, include it in your professional roadmap or try to incorporate it in your organization.
Wikipedia describe it as
“Data science is an interdisciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from noisy, structured and unstructured data, and apply knowledge and actionable insights from data across a broad range of application domains.”
I have highlighted and hyperlinked certain words because those are the key to understand Data Science. Data Science is not a single operation, in a large organization a “Data Science Process” is often done by an entire team, each individual specialized in their domain, chipping in.
Data Science Process Flow -Deconstructed (The Purpose)

A Typical Data science problem or process can be further divided into this following section.
- Frame the problem: This is where an individual or an organization defines what problem they are trying to address or what is their goal to achieve. Here is a list of common uses of a typical data science project.
- Identify and Refine “Target/goal” aka Data Driven Quantifiable Decision making
- Fraud Detection
- Recommendation system
- Help to follow “best Practice” and issues that “matters”
- Risk assessment and Mitigate planning
And the list goes on.
 2:Collect Data: This is where a data scientist collect data from users or accessing a database. Data Architect and Data Engineers are often consulted in this step to make sure the data is accessible and meets all its requirements to be used in a project. This part of Data collection and next one Data Cleaning is the most time consuming and vital step of the process
2:Collect Data: This is where a data scientist collect data from users or accessing a database. Data Architect and Data Engineers are often consulted in this step to make sure the data is accessible and meets all its requirements to be used in a project. This part of Data collection and next one Data Cleaning is the most time consuming and vital step of the process
3: Process the Data: here a Data scientist (with the help of other Data “fairies”) help to clean, concise, condition and preprocess the data. Data Collection and Cleaning most of the time comprises of 60-65% of a data Science project time (figure 1)
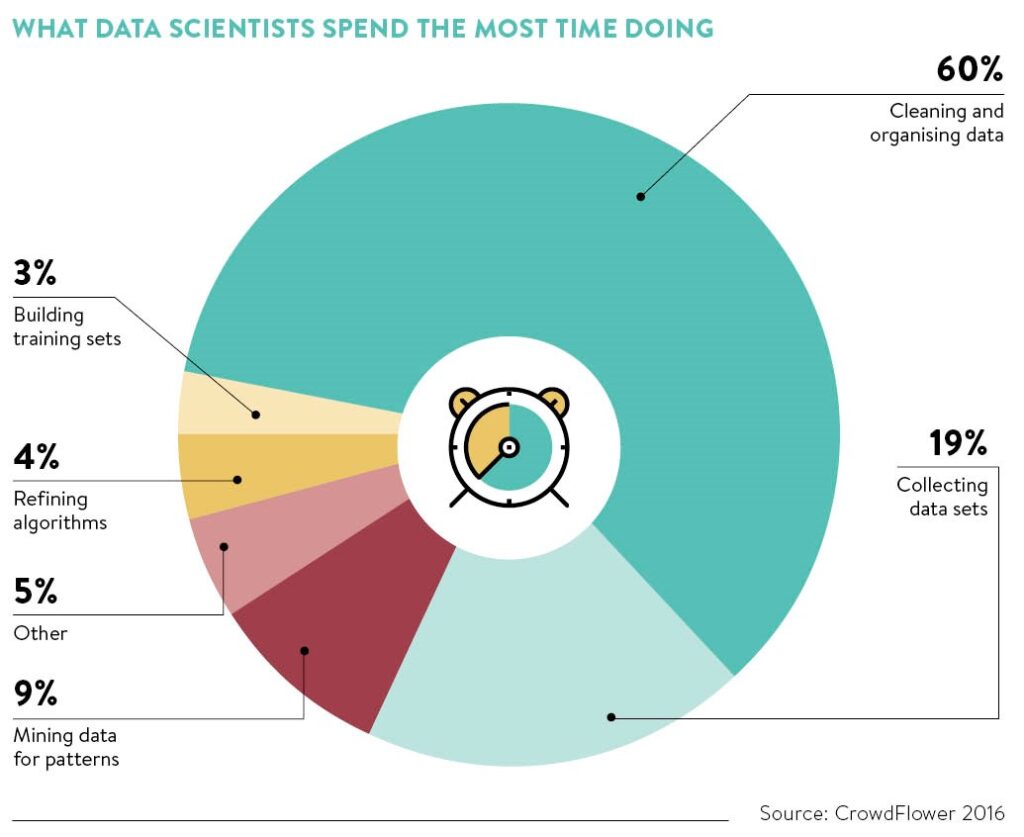
Figure 1: Generic Data Science process flow and breakdown of times(CrowdFlower 2016)
4: Explore the Data: here data is looked at in depth for patterns, hidden trends etc. Multiple plots, visuals, operations are used in this step.
5: Model Building/ In depth Analysis: Here the data scientist work with the data to figure out the most suited and optimal model to use. They do hypothesis testing, split data into test and training set, select and tune features, tune hyperparameters, run automatic model selection-test-validation etc. They use analytics, Machine learning (supervised and unsupervised), Artificial Intelligence (AI) and Natural Language Processing (NLP) depending on the problem they are trying to solve.
 Figure 2: Data Science deconstructed
Figure 2: Data Science deconstructed
6: Communicate result: In this step they communicate the results with the end user and see if this solution is good enough. Often there is a round or “iteration” happens in this part of process and once the model is final, it gets deployed and monitored for further tuning.
Tools and Technology (The weapon)
 You will never find a data scientist who doesn’t like a picture over words, they are indeed very graphic people. So, I will start this section with this borrowed image explaining the most used and needed tools in the process. This list is ever-growing and by no means suggestive. This is a good checklist of reference for aspirant data scientist or a person scouting for Data Science service providers.
You will never find a data scientist who doesn’t like a picture over words, they are indeed very graphic people. So, I will start this section with this borrowed image explaining the most used and needed tools in the process. This list is ever-growing and by no means suggestive. This is a good checklist of reference for aspirant data scientist or a person scouting for Data Science service providers.
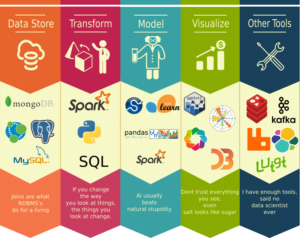
Figure 3: tools of Data Science (courtesy bigdata. Black)
The interconnected discipline serving data (The Gang)

As I mentioned before there are other discipline names and people, we hear often associated with data science (such as ML engineers, Computer Scientist, Data Engineers etc) and we are sometimes unsure where they fit in a data science project. In this portion I designed a chalkboard graphics to explain how these separate fields are interconnected and where they add value. Data Science, Machine Leaning, Data Engineer/Architect work close to each other and in often overlap in their contribution in a project. The three Bubble shows three field and where they overlap in terms of the science and the flowchart is more from a project.
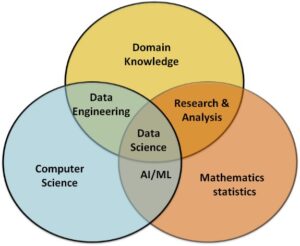
Figure 4: The interrelated field of Data Science
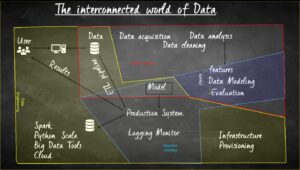
Figure 5: Interconnected world of Data




